Deep Learning vs Machine Learning/What’s the difference?
Na Ciência de Dados/Data Science, há muitos termos que são usados de forma intercambiável,
então vamos explorar os mais comuns, que são Big Data, Machine Learning, Data Mining, Deep Learning e Neural Networks.
O desenvolvimento simultâneo do enorme poder computacional disponível em redes distribuídas bem como as novas ferramentas e técnicas para análise de dados, ocasiona a atual realidade de que as organizações possuem o poder de analisar vastos conjuntos de dados.
Esse contexto faz com que um novo conhecimento e novas ideias estejam disponíveis para todos.
Sendo assim, podemos dizer que Big Data é um conceito terminológico que aponta que naquele momento estamos a lidar com um volume imenso de dados e que sistema de dados serão nossos alicerces na empreitada para a resolução de um determinado problema.
Nesse caminhar, utilizaremos, ou não, alguma ou algumas técnicas simples ou complexas do mundo computacional, dispostas tanto em algum sistema distribuído bem como localmente, em sua máquina , em seu computador.
Qualquer que seja a configuração, no bojo do sistema que irá processar os dados e ajudá-lo na transformação desses entes em informações relevantes, em decisões que gerem valor, possui de forma latente conhecimentos de campos como a Estatística ou a Matemática, bem como subárea como a visualização de dados, etc.
Esse tipo de sistema também pode também ser visto, na literatura da área, como uma estrutura suportada e sustentada em cinco (05) pilares ou, como comumente dito, por cincos V’s: Velocidade, Volume, Variedade, Veracidade e Valor.
Esse conjunto de dados são tão maciços, tão variados e tão rapidamente construídos (a quantidade de ligações realizadas por um determinado sistema de telefonia celular e dados gerados por essas mesmas ligações, quantidade de comentários de um nicho de vídeos no Youtube, dados gerados por uma malha de sensores em uma determinada fase de perfuração, etc) que desafiam os métodos de análise tradicionais.
São os recursos computacionais distribuídos e seu enorme poder de processamento atrelado ao (re) surgimento de técnicas de análise de grandes volumes de dados que nos últimos tempos criaram a possibilidade de que essa outrora montanha inútil de dados pudessem gerar valor nas companhias.
A Mineração de dados/Data Mining é o processo de pesquisa e análise automática desses dados, descobrindo padrões que não tinham sido revelados anteriormente. Ele envolve sempre um processo de tratamento dos dados, com o intuito de parametrizá-los em um formato mais apropriado, facilitando o processamento posterior, ocasionando uma menor exigência de recursos computacionais, de tempo de processamento, do tempo necessário para que o sistema aponte possíveis resoluções de um determinado problema .
Por isso, geralmente, existe uma etapa de pré-processamento dos dados, preparando-os e transformando-os em um determinado formato.
Depois que isso é feito é possível que determinados padrões ocultos, existentes no conjunto de dados, possam ser extraídos, utilizando um rol de técnicas de análises, que vão desde a simplicidade das técnicas de visualização de dados à complexos modelos estatísticos que suportam uma abordagem via Aprendizagem de Máquina/ Machine Learning.
A Aprendizagem de Máquina/ Machine Learning é um subconjunto da área da Inteligência Artificial, IA, que faz uso de algoritmos para que tomadas de decisão inteligentes possam ser realizadas através da análise de um grande volume de dados.
A peculiaridade desse arranjo, desse paradigma é de que essas decisões são feitas tendo como premissa que elas serão realizadas através da aprendizagem que esse sistema algorítmico desenvolve ao longo do tempo.
Indo além, esse aprendizado é um evento que acontece apesar de não ser explicitamente programado, sem ter sido suportado por regras pré estabelecidas, como normalmente acontece em modelos computacionais mais tradicionais e sim, que motivado nos exemplos e nos treinos que os dados disponíveis propiciam.
No final das contas podemos concluir que um sistema algorítmico, do tipo Machine Learning, usa técnicas para analisar dados e tomar decisões inteligentes com base no que é aprendido por esse sistema, via contato com um determinado sistema de dados volumosos, sem que nada tenha sido explicitamente programado, através de regras algorítmicas, como acontece tradicionalmente em sistemas do tipo.
As técnicas de Machine Learning pressupõe que o sistema aprenda com os exemplos contidos naquela infinidade de dados, com os padrões ali existentes, suas inferências e codependências e assim o proprio sistema consiga ir resolvendo problemas, bem como possa fazer previsões mais precisas e por conta propia.
A Aprendizagem Profunda/Deep Learning é um subconjunto especializado de Machine Learning, que faz uso de redes neurais em camadas para simular a tomada de decisões humanas.
Os algoritmos de Deep Learning podem rotular e categorizar informações e identificar padrões, conseguindo ter um aprendizado contínuo, melhorando a qualidade e a precisão dos resultados e, o mais importante, apontando se determinadas decisões estavam corretas.
As Redes Neurais Artificiais (RNA)/Neural Networks(NN), muitas vezes referidas como redes neurais, usam a inspiração das redes neurais biológicas —embora funcionem totalmente diferente destas— para através do uso de uma coleção de pequenas unidades computacionais, que chamamos de neurônios, possibilitem que os dados recebidos deflagrem, de modo autônomo, tomadas de decisões.
A disposição topológica dessas redes, feita em camadas aninhadas, que podem ser vistas como de certo modo aprofundadas, geram um contexto que ocasionam uma melhor análise dos dados mesmo quando esse volume de dados aumenta com o passar do tempo, tornando o esquema algorítmico mais eficiente, óbvio que até certo limite, invertendo um pouco a lógica de outros sistemas de aprendizagem, que começam a ter um desempenho espúrio a medida que o volume de dados aumenta.
Importante também que possamos esclarecer certa diferenciação entre IA e Ciência de Dados/Data Science.
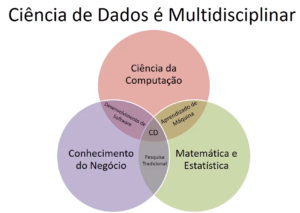
Ciência de Dados é o processo e o método para extrair conhecimento e insights de grandes volumes de dados diferentes. Devido ao desafio da tarefa, é um campo notadamente interdisciplinar, envolvendo a Matemática, Análise Estatística, conhecimento sobre o negócio, a visualização de dados bem como técnicas computacionais como Machine Learning e tantas outras —mescladas ou não— de IA ou outro paradigma computacional.
Neste caso vemos, por exemplo, que poderíamos fazer uso de algoritmos de Machine Learning bem como modelos de Deep Learning para extrair inferências e significados de um determinado conjunto de dados.
Tudo isso ocorre porque existe esse emaranhado interdisciplinar na Data Science, e é ele que viabiliza que possamos apropriarmo-nos de informações ou mesmo de padrões ocultos, encontrando significado e significância nos grandes volumes de dados que são gerados no nosso cotidiano, alcançando o grande objetivo da Ciências de Dados/Data Science no contexto empresarial, que é tomar melhores decisões que possibilitem impulsionar um determinado negócio.
Vemos assim que existe uma grande interação entre IA e Data Science, porém esse relacionamento não significa que podemos inferir que uma área é um subconjunto da outra.
Podemos tão somente definir que quando falamos de Data Science estamos de fato usando uma terminologia ampla e interdisciplinar por natureza, que engloba processamento de dados convencionais ou de Big Data, enquanto a Inteligência Artificial inclui técnicas que permitam que computadores consigam aprender a resolver problemas e tomar decisões inteligentes, com o sem o uso de Big Data.